{kind=link}
Hannes Heikinheimo
Sep 19, 2023
1 min read

In the past five years we've seen tremendous technological advancement in the voice and Natural Language Understanding (NLU) space. In 2016 we saw speech recognition reach human parity in some of the classical conversation speech recognition benchmarks. Alexa launched and Google introduced their assistant smart speaker. Speechly was founded with the idea that the asynchronous turn-based conversational model could be improved upon.
The advancement has continued, growing leaps and bounds in less than a decade. We now have superhuman accuracy in Automatic Speech Recognition (ASR) as well as Natural Language Understanding (NLU) for many of the most well known ASR and NLU benchmarks.
However, despite these technological advancements, voice as a User Interface (UI) and as a UI modality has yet to live up to its promises. Most people still only use voice technology as a way to hear the weather, turn off the lights in their home, or to voice search short queries in a browser.
The reason? While the technology has advanced, the user experiences have primarily remained the same, trapped in the context of a conversational assistant style experience. The end result is a gap between what the technology is capable of, what people want, and what current day voice UIs actually deliver.

Even something as ubiquitous as touchscreen technology didn't see widespread adoption until the introduction of the iPhone, which made the experience feel natural and intuitive. iPhone image credit: Rafael Fernandez, IPhone 1st Gen, CC BY-SA 4.0
For a modality to take off, it has to feel effortless - magical, even. Most of the technology and design approach today doesn't meet expectations.
That's a controversial hot take for a company rooted in the voice technology industry - but the only way that we advance and grow the industry is by looking at it objectively and working to build better, higher quality experiences.
So what is quality? The classical definition is that a product is of high quality when performance meets expectations. Let's look at why the improvement in technological quality has yet to result in improvements in user perception of quality.
People are very good at detecting fakes, and the closer something comes to resembling human behavior, the more the small deviations from this behavior start to feel disturbing. It's that shift into the uncanny valley where the creepiness outweighs the cool.
Many of the voice experiences over the last decade are reliant upon the assistant persona to manage the handoff into any third party applications. This ties the success of the voice channel to the voice assistant persona's ability to manage against the uncanny valley feeling. Voice experiences have been built as one-off applications, often with little to no visual elements. The tech has been focused on trying to make the AI feel like a human by forcing users into a conversation, with the idea that it will feel natural.
Humans cannot speak and listen at the same time. Therefore any conversational communication happening in these legacy assistant experiences is one direction at a time, and not simultaneous. As smart as the AI gets and as "human" as the technology is made to feel, it still doesn't resonate as a good experience because of how slowly information is exchanged.
On the other hand, it is easy for humans to process visual information and speak at the same time. When sighted people speak to each other, they're often watching for visual cues from the other person to show that they understand, or have a question, as they speak. With newer technology that leverages standard Graphical User Interface (GUI) elements, you can build a voice enabled experience for a human that includes a visible reaction on a screen to show understanding. In the voice-only experiences, this visual feedback is typically missing.
When you add voice to the visual UI you are making the machine more powerful, and the experience more intuitive. With Reactive Voice UIs the visual interface and the user communicate with one another in both directions simultaneously. The communication is fast. The experience feels natural.
From a user perspective, it's the difference between trying to interact with a peculiarly behaving almost-human to controlling a highly functioning machine. From the designer's perspective, it means having access to another tool in the toolkit to help drive UI design forward.
By leveraging the screen and existing user interface design best practices, building with voice starts to feel much more accessible and intuitive to both the user and the designer.
Screens are incredibly helpful when it comes to setting expectations and scoping the context of your UI. Voice-only experiences often give users analysis paralysis because there's no intuitive way to understand what they can do or say, and there's a limited understanding of what features are supported. Users are left to guess at what is possible, which means that they encounter a long list of things that are not possible along the way.
When voice-only assistants present the experience as infinite, it quickly becomes clear just how limited it can be.
Outside of voice, most applications are designed to do just a few things but to do those few things, and communicate what they are and how to use them, very well. If we apply that same idea to experiences with voice, the voice UI should use existing UI conventions and the visual elements of the screen to communicate the scope of what is possible to the user.
The gap between user expectations and value delivered to the user in many voice experiences can be significantly reduced by applying the design principles of Reactive Voice UIs to the design and development of voice experiences to help properly set expectations up front, and improve the delivery of the value by mapping it directly back to the user interface.
With Reactive Voice UIs, the designer builds in visual feedback elements that help the user better understand how and when to use voice for a more efficient experience. This can look like commonly understood elements such as a microphone button with a "Push to Talk" button or an overlay component that provides feedback about the voice input.
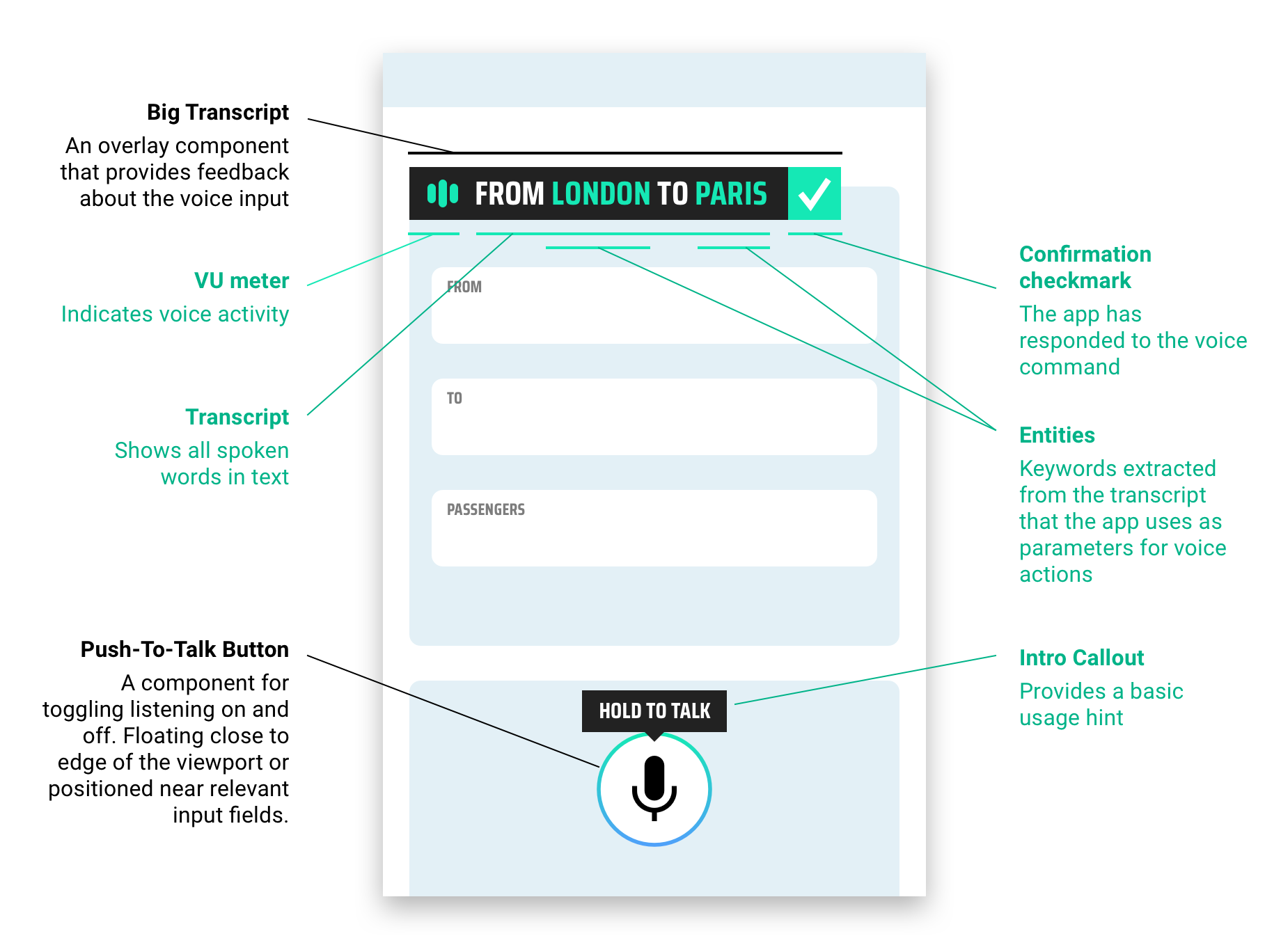
When these features are combined with a new technology called Spoken Language Understanding™ (SLU), it allows the user to speak and have the UI instantly map their words to actions within the UI. In practice, SLU and a Reactive Voice UI come together to create experiences like this:
It feels almost…magical.
Cover photo by Andrea Piacquadio on Pexels
Speechly is a YC backed company building tools for speech recognition and natural language understanding. Speechly offers flexible deployment options (cloud, on-premise, and on-device), super accurate custom models for any domain, privacy and scalability for hundreds of thousands of hours of audio.
Hannes Heikinheimo
Sep 19, 2023
1 min read
Voice chat has become an expected feature in virtual reality (VR) experiences. However, there are important factors to consider when picking the best solution to power your experience. This post will compare the pros and cons of the 4 leading VR voice chat solutions to help you make the best selection possible for your game or social experience.
Matt Durgavich
Jul 06, 2023
5 min read
Speechly has recently received SOC 2 Type II certification. This certification demonstrates Speechly's unwavering commitment to maintaining robust security controls and protecting client data.
Markus Lång
Jun 01, 2023
1 min read