Hannes Heikinheimo
Sep 19, 2023
1 min read
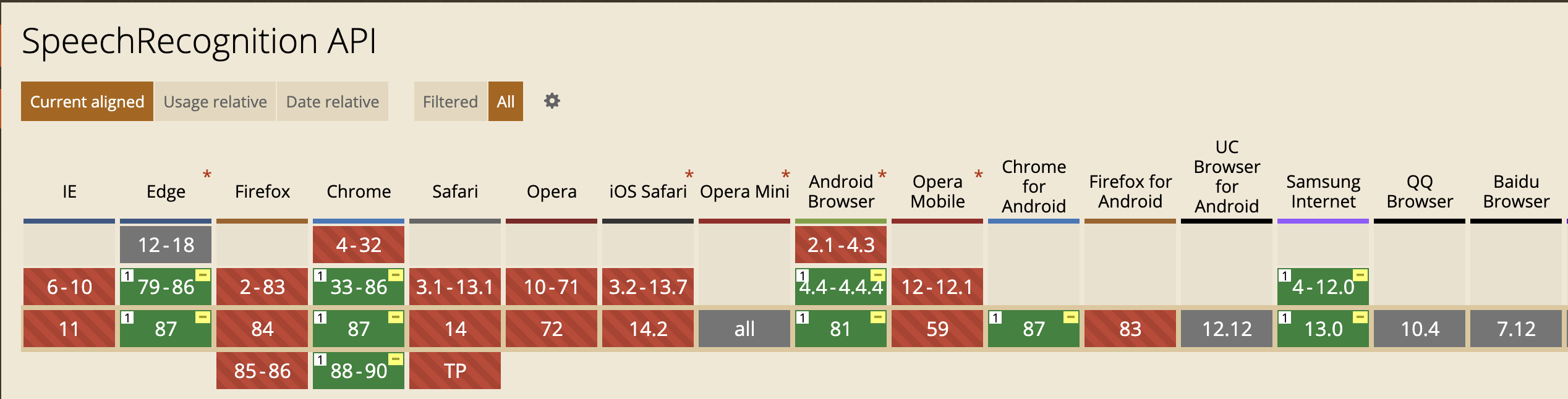
The most used tool for voice user interfaces on the browser is the Web Speech API and SpeechRecognition API, but there are major limitations with both technologies.
First, Web Speech API is only available for Chrome. SpeechRecognition API is also available for Firefox and some derivates of these, but the low support makes them unfeasible for production use in any real-life application.
Second, Web Speech API and SpeechRecognition API provides only the transcription of the user's speech. They don't provide any context or meaning (natural language understanding) for this input. While in some use cases that only need the transcription it's not an issue, for more complicated user tasks and for building user interfaces natural language understanding needs to be solved somehow.
Speechly is the first developer tool built from the ground up for building voice user interfaces. Our Spoken Language Understanding API integrates speech recognition (ASR) and natural language understanding (NLU) to a single Spoken Language Understanding API for low latency and improved accuracy.
In addition to wide browser support, Speechly is available for touch screen platforms (Android, iOS and React Native) which makes building cross-platform applications very simple. This makes Speechly the best WebSpeech API alternative for voice user interfaces.
One important aspect when comparing voice APIs is of course the speech recognition accuracy. Speechly benefits from the fact that it's always configured for a certain use case and this configuration is used to bias the speech recognition model.
Biasing helps Speechly correctly catch product names, professional lingo and other harder words. Even without biasing, our speech recognition accuracy is on par with Google's WebSpeech API, as you can see in the video below.
In the video, a standard, non-biased Speechly model is running simultanously with the Google Webspeech API test and both are transcribing Steve Jobs' keynote speech in the first iPhone launch event.
Natural language understanding is a branch of machine learning that enables computer systems to extract meaning from text or speech input. It reduces natural language into structured data that typically consists of intents and entities (slots) that modify these intents.
While this might sound complicated, let's give a simple example to clarify it. If the user says something like "Show t-shirts", the user intent is probably something like "show_products" and it has an entity "t-shirt". Naturally, the user might also say something like "Show jeans". In this case, the entity would be the same – "show_products" but the entity would be "jeans".
If we are 100% sure that our users will always use either of these two utterances in exactly this format, we can use a very simple regular expression as our natural language understanding algorithm.
But most often this is not the case. Rather, the user can express this same intent in many different ways. Maybe they say something like "I'd like to see turtlenecks" or "Do you have any tees?"
A good natural language understanding algorithm can extract the meaning out of all these utterances and always return with the same intent and entity, no matter how the user expresses themselves.
WebSpeech and SpeechRecognition APIs don't have any natural language understanding capabilities and if you need that, you'll need to start learning SpaCy or some other natural language understanding tool. This increases development time significantly and adds complexity.
Now as we've learned, a voice user interface needs two distinct parts: speech recognition to transform user speech into text and natural language understanding to extract meaning (intents and entities) from that text. WebSpeech and SpeechRecognition APIs only offer speech recognition.
If you have ever used Google Assistant, Alexa, or Siri, you've probably seen that while the text transcript appears in near real-time while the user speaks, when the user stops speaking there is a small delay after which the action happens. This is where the natural language understanding happens and the action that the user wanted is performed.
Speechly is a Spoken Language Understanding API that provides both of these functions in a fully streaming fashion. When the user starts talking, the API begins returning both the transcript and the "meaning", eg. intents and entities for this input. This makes applications built with Speechly very responsive and fast to react to user input.
In fact, Speechly returns both interim and final results for both the transcript and for intents and entities for even faster feedback.
Unlike SpeechRecognition or WebSpeech API, Speechly browser-client is supported by all modern browsers on mobile and desktop. You can also use Speechly for iOS and Android and we are adding more client libraries in the future, too. You can find all our client libraries here for up-to-date status.
The streaming fashion of Speechly enables natural end-user utterances such as "Show me t-shirts... sorry I mean jeans". For most other voice UI APIs, this kind of query fails because of end pointing (or failure in natural language understanding): the system recognizes the small pause in between as a signal for the end and starts processing the first part of the utterance without taking into account the last part.
Another important thing that streaming enables is real-time visual feedback. If we think about our example utterance "Show t-shirts" it can show the t-shirts as soon as the user has stopped speaking. This encourages the user to go on and they can continue with something like "for men... in size large".
Configuring the natural language understanding model on Speechly is very simple and can be done either in our web dashboard or by using our command line tools. The former works great for simple projects and initial models and the latter is better for projects with several developers collaborating on the same model.
Here's a quick demo showing this a web application built with Speechly Spoken Language Understanding in action:
As you can see from the demo, real-time visual feedback is the key to natural voice user interfaces. We believe that the lack of real-time feedback is the reason, why the "iPhone moment" has not happened yet for voice UIs. This kind of real-time feedback can't be done with either WebSpeech or SpeechRecognition API.
You can see the differences between responsiveness also by checking out this GitHub project that is using WebSpeech API for a chess game. Then compare it to this video which shows a similar (albeit more simple!) chess game built with our JavaScript client.
Just like the iPhone succeeded with the touch screen because of its very responsive and intuitive user experience, voice UIs need the same responsiveness and intuitiveness to really succeed.
Amazon Transcribe is Amazon's text-to-speech API that suffers from the same limitations than WebSpeech API and SpeechRecognition API.
While it does offer accurate speech recognition, it does not have natural language understanding capabilities, which makes it slow and non-responsive for voice user interfaces.
IBM Watson Speech to Text is another paid for speech-to-text API that does not include NLU capabilities.
Microsoft Bing Speech API is Microsoft's answer to speech recognition, but unfortunately does not support natural language understanding either.
Assembly AI offers great features for speech to text, including profanity filters and multiple models for different accents. It's a bit cheaper than the other altenatives, but does not support NLU, either.
Speechly offers fully streaming real-time Spoken Language Understanding API for integrating responsive voice user interfaces for any web application.
Building voice user interfaces for browser applications can't be done without natural language understanding capabilities. While it is possible to use another tool for speech recognition and another for NLU, it adds complexity and most probably increase latency so that real-time visual feedback is not achievable.
This makes Speechly the only available tool that enables complex voice user interfaces in browser with a single API and with wide support for different browsers.
If you are interested in building real-time voice user interfaces for React or JavaScript, you can start using Speechly by completing our tutorials. You can follow either the React tutorial or JavaScript tutorial depending on the platform you are developing on.
If you want to learn more about what kind of applications Speechly enables, you can refer to our Use cases section.
Speechly is a YC backed company building tools for speech recognition and natural language understanding. Speechly offers flexible deployment options (cloud, on-premise, and on-device), super accurate custom models for any domain, privacy and scalability for hundreds of thousands of hours of audio.
Hannes Heikinheimo
Sep 19, 2023
1 min read
Voice chat has become an expected feature in virtual reality (VR) experiences. However, there are important factors to consider when picking the best solution to power your experience. This post will compare the pros and cons of the 4 leading VR voice chat solutions to help you make the best selection possible for your game or social experience.
Matt Durgavich
Jul 06, 2023
5 min read
Speechly has recently received SOC 2 Type II certification. This certification demonstrates Speechly's unwavering commitment to maintaining robust security controls and protecting client data.
Markus Lång
Jun 01, 2023
1 min read